
OpenAI는 2024년 2월 15일, Text-to-Video 생성형 AI인 Sora를 발표했다. 이후 국내외 방송·영상 업계에는 기대감과 함께 많은 일자리가 대체될지도 모른다는 위기감이 공존하고 있다. 본고에서는 비전(vision) 분야에서 생성형 AI의 발전과정과 Sora의 등장으로 인한 기대감과 Sora에서 발견되고 있는 오류, Sora를 활용한 영상 제작 사례를 알아보고 Sora와 같은 영상 분야 생성형 AI의 발전이 관련 산업에 미치게 될 영향에 대해서 전망해 보고자 한다.
1. 들어가며
OpenAI가 2024년 2월 15일, 텍스트를 영상으로 만들어주는(Text-to-Video) 생성형 AI인 Sora를 발표한 이후 국내외를 막론하고 방송·영상 업계에서는 하나같이 기대감과 함께 위기감을 표하고 있다. 그리고 곧이어 이 서비스를 분석하고 전망한 전문가들의 칼럼이나 학술대회 발표가 이어지고 있다. OpenAI는 Sora를 공개하면서 이 서비스의 기술적 세부 사항에 대한 공식 연구 논문을 발표하지는 않았지만, 활용된 기술에 대한 개요와 일부 정성적 결과를 다룬 기술 문서(technical report) ‘Video generation models as world simulators’를 웹사이트에 발표했다1). 그리고 Sora 서비스를 일부 시각예술가, 디자이너, 영화제작 전문가들에게만 제한적으로 공개하여 서비스의 완성도를 테스트 중이고 연말에는 이 서비스를 대중에까지 이용할 수 있도록 하겠다고 발표했다. 그동안 OpenAI는 Sora 서비스에서 발생할 수 있는 부정확한 정보(misinformation), 혐오 콘텐츠(hateful content), 편향(bias)을 테스트할 레드 팀(red team)2)을 운영할 것이라고 밝혔다(OpenAI, 2024).
본고에서는 비전 분야에서 생성형 AI의 발전과정과 Sora의 등장, Sora에서 발견되고 있는 오류, Sora를 활용한 영상 제작 사례를 알아보고 Sora의 발전이 관련 산업에 미치게 될 영향에 대해서 전망해 보고자 한다.
- 1) https://openai.com/index/video-generation-models-as-world-simulators/
- 2) 서비스의 문제점이나 취약점을 찾아내기 위해 외부에서 서비스를 공격(테스트)하는 팀
2. GAN부터 Sora까지... 비전 분야 생성형 AI의 발전
이미지 분류 분야에서 획기적인 알고리즘으로 등장한 CNN(Convolutional Neural Networks)이 발표된 2012년 이후로 한동안 이미지, 영상과 관련한 연구는 주로 객체를 분류하고 인식하는 컴퓨터 비전(computer vision)에 초점이 맞추어져 있었다. 이 당시 AI는 사람의 눈을 대신하는 역할을 할 수는 있지만 사람의 창의성과 창작력을 대신하기에는 어렵다는 시각이 많았다. 이러한 선입견은 2014년 이안 굿펠로(Ian Goodfellow)3)가 GAN(Generative Adversarial Network, 생성적 적대 신경망)을 개발하면서 전환기를 맞게 된다. GAN은 데이터의 학습을 통해 가짜 예제를 만드는 생성모델(generator)과 생성모델이 제시하는 가짜 예제와 실제 예제를 최대한 정확하게 구분할 수 있도록 훈련된 판별모델(discriminator) 간의 경쟁을 통해 이미지, 음성 등을 만들어내는 방식이다. 그래서 최종 결과물로 실제 예제와 매우 비슷한 가짜 예제를 생성하게 되며 이것이 인간의 창의성을 흉내 낼 수 있게 됐다. 비전 분야의 생성형 AI 기술은 GAN과 함께 그와 유사한 시기에 개발된 VAEs(Variational Autoencoders), Diffusion Model 등 이미지를 생성하는 기술 위주로 발전하게 되며 상용서비스로는 Midjourney(Midjourney Inc.), Stable Diffusion(Stability AI), DALL-E(OpenAI) 등이 출시됐다. 이 서비스들은 환각(hallucination), 가짜뉴스, 저작권 침해 문제 등이 이슈가 되고 있지만, 기술적 결함을 개선하고 새로운 이미지를 창작하는데 점점 어색함이 줄어든 결과물을 냄으로써 점차 다양한 분야에서 활용이 늘고 있다(EC-PR, 2024; Medium, 2024a).
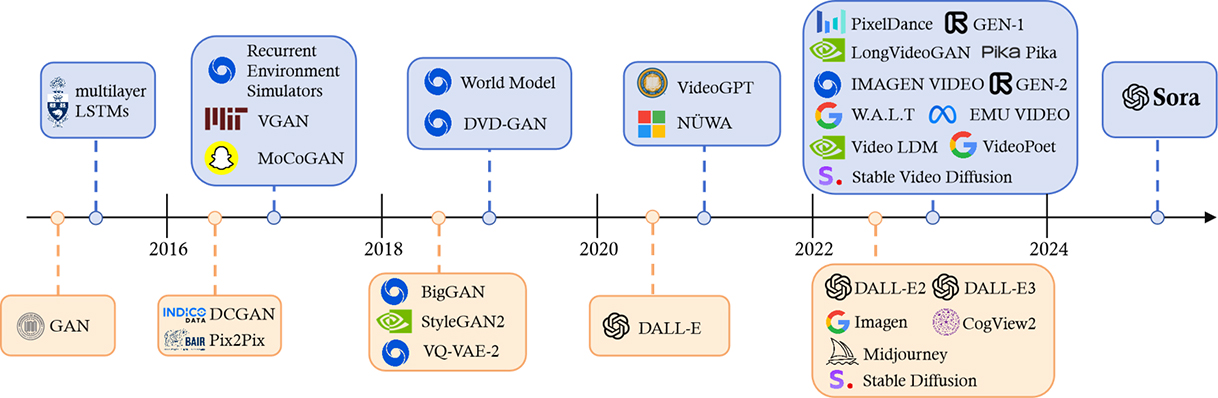
History of Generative AI in the Vision Domain
- ~ 2016
- GAN
- multilayer, LSTMs
- 2016 ~ 2018
- INDCO DATA, DCGAN, BAIR, Pix2Pix
- Recurrent Environment Simulators, VGAN, MocoGAN
- 2018 ~ 2020
- BigGAN, StyleGAN2, VQ-VAE-2
- World Model, DVD-GAN
- 2020 ~ 2022
- DALL-E
- VideoGPT, NUWA
- 2022 ~ 2024
- DALL-E2, DALL-E3, Imagen, CogView2, Midjourney, Stable Diffusion
- PixelDance, GAN-1, LongVideoGAN, Pika, IMAGEN VIDEO, GAN-2, W.A.L.T, EMU VIDEO, Video LDM, VideoPoet, Stable Video Diffusion
- 2024 ~
- Sora
이미지 생성형 AI는 빠른 발전을 거듭했지만 그보다 더 어려운 기술로 알려진 영상 생성형 AI는 일반인들이 만족할 만한 서비스가 이보다 늦게 출시됐다. 영상 생성은 이미지 생성에 비해서 캐릭터, 배경 등이 프레임 간에 일관되게 유지되고 다른 것으로 변형되거나 휘어지지 않는 시간적 일관성(temporal coherence)이 유지되어야 한다. 이러한 시간적 일관성은 단 몇 초에 그쳐서는 안 되며 비교적 긴 시간동안 유지되어야 한다. 그리고 시간적 일관성을 보장하지 못할 경우 생성할 수 있는 영상의 길이는 몇 초에 머물게 된다. 그리고 영상 생성에서는 장면에서 발생하는 상황과 함께 카메라가 움직이는 방식도 제어해서 영상 출력물을 만들어 내야 하는 점도 하나의 프레임만 창작하는 이미지 생성형 AI와의 차이라고 할 수 있다(Andreessen Horowitz, 2024).
많은 스타트업과 빅테크 기업들이 영상을 위한 생성형 AI 서비스를 시도했다. 표1은 2023년 12월을 기준으로 영상 분야의 생성형 AI 서비스 현황을 나타낸 것이다. 이들 중 주요 서비스로는 Gen-2(Runway), Pika(Pika), Stable Video Diffucion(Stability AI) 등이 있다. 이 표에는 나와 있지 않지만, 빅테크 기업 중에는 메타의 Emu Video, 구글의 VideoPoet, 바이트댄스의 MagicVideo 등의 서비스가 있다. 이들 서비스 대부분에서 제작된 영상에 오류가 발견됐으며, 영상의 길이도 단 몇 초 정도로 짧고 시간적 일관성에 있어서도 완성도가 비교적 낮았다. 그리고 대부분의 서비스는 아직 보고서 또는 데모 영상을 공개하는 수준이며 일반인들에게는 서비스를 제공하고 있지 않다(Andreessen Horowitz, 2024).


| Company | Generation Type | Max Length | Extent? | Camera Controls? (zoom, pan) |
Motion Controls? (amount) |
Other Features | Format |
|---|---|---|---|---|---|---|---|
| Runway | Text-to-video, image-to-video, video-to-video | 4 sec | Yes | Yes | Yes | Motion brush, upscale | Website |
| Pika | Text-to-video, image-to-video | 3 sec | Yes | Yes | Yes | Modify region, expand canvas, upscale | Website |
| Genmo | Text-to-video, image-to-video | 6 sec | No | Yes | Yes | FX presets | Website |
| Kaiber | Text-to-video, image-to-video, video-to-video | 16 sec | No | No | No | Sync to music | Website |
| Stability | Image-to-video | 4 sec | No | No | Yes | Local model, SDK | |
| Zeroscope | Text-to-video | 3 sec | No | No | No | Local model | |
| ModelScope | Text-to-video | 3 sec | No | No | No | Local model | |
| AnimateDiff | Text-to-video, image-to-video, video-to-video | 3 sec | No | No | No | Local model | |
| Morph | Text-to-video | 3 sec | No | No | No | Discord bot | |
| Hotshot | Text-to-video | 2 sec | No | No | No | Website | |
| Moonvalley | Text-to-video, image-to-video | 3 sec | No | No | No | Discord bot | |
| Deforum | Text-to-video | 14 sec | No | Yes | No | FX presets | Discord bot |
| Leonardo | Image-to-video | 4 sec | No | No | Yes | Website | |
| Assistive | Text-to-video, image-to-video | 4 sec | No | No | Yes | Website | |
| Neural Frames | Text-to-video, image-to-video, video-to-video | Unlimited | No | No | No | Sync to music | Website |
| Magic Hour | Text-to-video, image-to-video, video-to-video | Unlimited | No | No | No | Face swap, sync to music | Website |
| Vispunk | Text-to-video | 3 sec | No | Yes | No | Website | |
| Decohere | Text-to-video, image-to-video | 4 sec | No | No | Yes | Website | |
| Domo Al | Image-to-video, video-to-video | 3 sec | No | No | Yes | Discord bot | |
| Full Journey | Text-to-video, image-to-video | 8 sec | No | Yes | No | Lipsyncing, face swap | Discord bot |
영상 생성형 AI 서비스의 출시는 2024년에도 계속 이어졌다. 1월에 구글이 Lumiere를 발표했고, 2월에는 Chat-GPT, Dall-E를 출시했던 OpenAI가 Sora를 발표했다.
- 3) 미국의 컴퓨터 과학자이자 엔지니어, 경영자인 이안 굿펠로(Ian Goodfellow)는 인공 신경망, 딥러닝 등 연구로 잘 알려졌으며, AI 전공하던 박사과정 당시, GAN 기술을 최초로 제안하였다.
3. 공개된 Sora, 그 혁신과 한계
2024년 1월 24일, 구글은 새로운 영상 생성형 AI 서비스인 Lumiere를 발표했다. 구글은 Lumiere 데모 영상을 통해 고화질이면서, 프롬프트에서 묘사한 것을 비교적 충실히 반영한 동영상을 생성한다는 것을 보여줬다. 그러나 생성 영상의 길이는 여전히 5초로 짧았고 데모영상에서 소개한 생성 영상은 고정된 카메라가 촬영하는 듯한 영상이었으며 주로 하나의 객체만 화면에 담았다.

2월 15일 공개된 OpenAI의 Sora는 그에 비해 더욱 발전된 형태의 영상 생성 기능을 보여줬다. 이 서비스는 카메라가 이동하며 촬영한 영상이나 특정 피사체를 확대(zoom in) 또는 축소(zoom out)한 영상을 생성할 수 있었다. 하나의 카메라가 아니라 여러 대의 카메라가 촬영을 하여 편집한 듯한 영상도 생성하는 게 가능했는데 이것은 기존 서비스들에서는 보기 어려운 방식이었다. 무엇보다도 피사체(캐릭터, 배경, 객체 등)가 비교적 수 초간 시간적 일관성을 유지하는 것은 기존의 생성형 AI 서비스보다 진일보한 형태였다. OpenAI는 Sora가 1080×1920의 해상도로 최대 1분인 영상의 생성이 가능하다고 발표했는데, 이는 Sora가 시간적 일관성을 비교적 긴 시간동안 유지할 수 있기 때문이다.
Sora는 이전에 공개됐던 영상 생성형 AI 서비스들이 가지고 있던 문제점을 극복한 혁신적인 서비스로 많은 사람들을 놀라게 했다. 언어에 대한 깊은 이해를 바탕으로 이용자의 지시에 표현된 요구사항을 정확하게 이해하고 이를 현실세계의 물리적, 화학적 법칙에 따라 구현했다. 이러한 장점은 비록 제한된 분야와 상황 하에서 아직 기초적인 단계이긴 하지만, 원인이 되는 행동이 발생할 경우 그에 따른 결과를 예측하는 기능 즉 물리세계에 대한 시뮬레이션을 가능하게 했다(Medium, 2024b)5).



미국 HarryX에서 Sora가 제작한 영상 4개와 사람이 촬영한 영상 4개로 1,000명의 성인들을 대상으로 조사한 결과에 의하면, 이들 중 상당 수는 Sora에서 생성한 영상과 사람이 녹화한 영상을 제대로 구별하지 못하는 것으로 나왔다. Sora가 만든 영상 중 한 고화질 영상(Big Sur의 Garay Point Beach 영상)에 대해서는 응답자의 60%가 사람이 촬영한 것으로 잘못 인식했고, 정작 사람이 촬영한 영상 중 하나에 대해서는 응답자의 64%가 Sora가 제작한 것으로 잘못 인식했다(Variety, 2024).
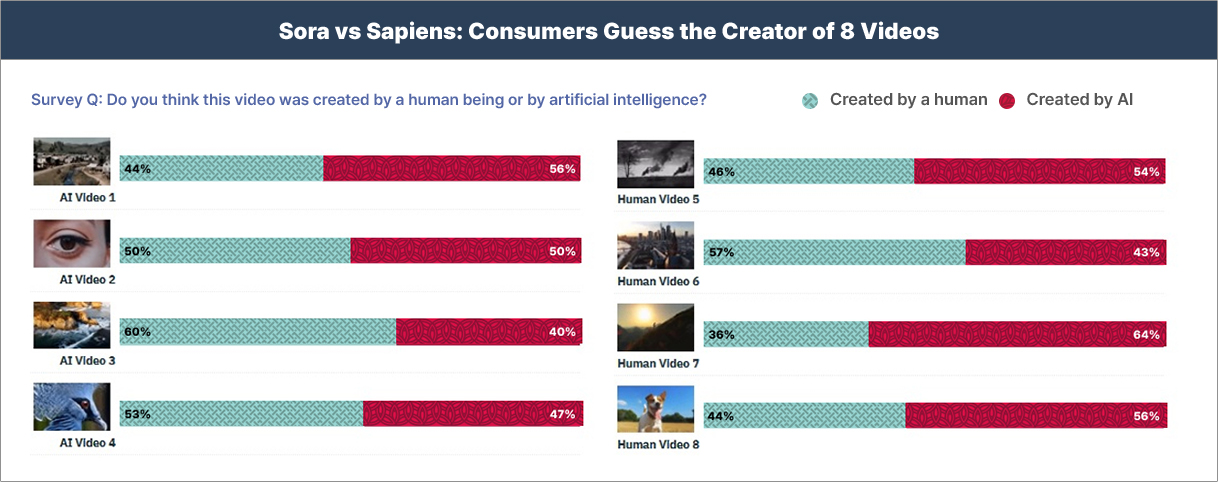
Sora vs. Sapiens: Consumers Guess the Creator of 8 Videos
Survey Q: Do you think this video was created by a human being or by artificial intelligence?
- AI Video 1 Created by a human : 44% Created by AI : 56%
- AI Video 2 Created by a human : 50% Created by AI : 50%
- AI Video 3 Created by a human : 60% Created by AI : 40%
- AI Video 4 Created by a human : 53% Created by AI : 47%
- Human Video 5 Created by a human : 46% Created by AI : 54%
- Human Video 6 Created by a human : 57% Created by AI : 43%
- Human Video 7 Created by a human : 36% Created by AI : 64%
- Human Video 8 Created by a human : 44% Created by AI : 56%
기존의 다른 영상 생성형 AI와 비교하여 많은 장점이 있음에도 불구하고 OpenAI Sora는 아직 많은 한계와 문제점을 갖고 있다. Sora는 물리적 규칙을 사람이 명시적 프로그램으로 입력한 것이 아니라 데이터를 통해 학습하기 때문에 모든 상황에 대한 충분한 데이터를 학습하지 못할 경우 실제 상황의 모든 물리적 규칙을 구현하기 어렵다. 따라서 특정 상황에서 원인과 결과의 구체적인 인과관계를 이해하지 못하는 경우가 있으며, 복잡한 장면에서는 물리적 규칙을 적용한 상황을 시뮬레이션하는데 어려움을 겪을 수 있다. OpenAI는 Sora를 공개하면서 이 서비스가 아직 해결하지 못한 오류 사례들을 함께 공개했다. Sora가 공개한 생성 영상에서 특정 캐릭터, 동물 또는 물체가 시간이 지남에 따라 사라지거나 변형되거나 복제되는 것이 발견됐다. 또한 농구공이 농구대를 통과하거나, 의자가 떠다니면서 움직이는 등 일부 영상은 일반적인 물리학과 모순된 현상을 보여줬다.


- 4) Google Research 유튜브 채널에서 발췌(Introducing Lumiere: A space-time diffusion model for video generation, https://www.youtube.com/watch?v=f9ThAzZs32M)
- 5) OpenAI가 Sora의 공개와 함께 발표한 기술 문서의 제목도 ‘Video generation models as world simulators’(세계 시뮬레이터로서의 영상 생성 모델)이었다.
4. Sora 공개 이후 진행된 다양한 시도
현재 Sora는 일부 시각예술가, 디자이너, 영화 제작자들에게만 이용권한이 부여된 상황이며, Sora를 먼저 사용한 전문가들은 다양한 영상 제작을 시도하고 있다. 캐나다 토론토의 미디어 제작기업인 Shy Kids는 머리 대신 노란색 풍선을 달고 있는 남자를 주인공으로 하는 단편영화인 ‘Air Head’를 제작했다. 단편영화 감독인 Paul Trillo는 인디밴드 Washed Out의 싱글앨범 ‘The Hardest Part’의 뮤직비디오를 Sora로 제작했다.6) 영국 런던의 XR 제작기업인 Oraar Studio의 공동창업자이자 크리에이티브 디렉터인 Josephine Miller는 Sora를 활용하여 창의적인 수중장면 영상을 제작했다(Underwater Sora Exploration). Don Allen Stevenson는 기린 머리를 한 플라밍고(홍학), 날개달린 돼지, 말 머리를 한 파리 등 현실에는 없는 잡종동물들을 소개한 다큐멘터리 영상을 제작했다(Beyond Our Reality). OpenAI는 유튜브 채널을 통해 Sora로 제작된 영상들을 공개하고 있다. OpenAI의 유튜브 채널에 공개된 영상들은 모두 고화질이며 머리가 풍선인 사람(Air Head), 특이한 의상을 입고 수중에 있는 사람(Underwater Sora Exploration) 등 다소 독특하고 상상의 세계를 담은 영상들이다.


- 6) 이 뮤직비디오의 길이는 4분 3초인데, Paul Trillo 감독은 Sora로 생성한 영상들을 Adobe Premiere로 연결했다고 한다.
5. 영상 생성형 AI의 발전이 관련 산업에 일으킬 변화
앞에서 언급한 바와 같이, 현재 Sora와 같은 영상 생성형 AI는 기술적으로 불완전하고 여러 오류를 보여주고 있다. 그러나 이 분야의 기술 발전 속도가 매우 빠른 것을 감안할 때 가까운 미래에 이러한 기술적 결함이 상당 부분 해소될 수 있을 것이며, 이 경우 영화, 미디어 산업뿐만 아니라 다른 산업에도 적지 않은 변화를 일으킬 것으로 예상된다.
미국 리하이 대학교의 Lichao Sun 교수 연구팀은 Sora 서비스를 기술적으로 검토한 논문을 발표하면서 향후 이 서비스가 영화·영상 산업뿐만 아니라 교육, 게임, 보건의료, 로봇공학 등에 활용될 것으로 전망했다(Liu et al., 2024). 이외에도 많은 칼럼과 보고서에서 영상 생성형 AI가 관련 산업에서 어떤 변화를 일으킬지 다양하게 전망하고 있다(Intuz, 2024; Acer Corner, 2024; 한혜진, 2024).
5.1. 영상제작
우선 많은 분석들에서 Sora의 등장이 영상제작 업계에 큰 영향을 줄 것으로 보고 있다(Liu et al., 2024; Intuz, 2024). 텍스트 입력만으로 영상을 제작할 수 있기 때문에 소요되는 비용과 시간을 절감하면서 영상의 일부 장면 또는 대부분의 장면을 제작하는데 활용될 수 있을 것이기 때문이다. 현재는 기술적으로 완전하지 않기 때문에 영상의 일부 장면을 제작, 편집하는 데 부분적으로만 활용되거나 짧은 모바일 동영상(숏폼 등)을 제작하는데 활용될 수 있다. 그러나 향후 이 기술이 고도화될 경우에는 고화질의 완성도 높은 영상의 제작이 가능해질 것이다. 이것은 영상제작의 진입장벽을 낮춰서 지금보다 더 많은 사람들이 낮은 비용과 적은 시간으로 이 분야에 참여하도록 하는 ‘영상 제작의 민주화(democratization of filmmaking)’를 확산시킬 수 있다. 이와 같은 상황에서는 영상 스텝들의 노하우 또는 촬영술에 대한 중요성이 점차 줄어들 것이며 영상에 대한 논리적인 상상력과 기획력이 중요해질 것으로 예상할 수 있다. 그리고 사람들에게 감동과 즐거움을 주는 스토리텔링과 콘텐츠IP에 대한 중요성이 더 강조될 것으로 예상되고 있다.
고도화된 영상 생성형 AI는 영상 촬영단계에서의 비용과 시간을 절감할 수 있을 뿐만 아니라 영상기획 단계와 영상 유통 단계에서도 활용될 수 있다. 생성형 AI는 영상기획 단계에서 구성원들 간의 협업을 위한 스토리보드, 프리비즈 등을 제작하는데 활용될 수 있다. 개봉 예정인 영화, TV프로그램에 대한 티저, 예고편 영상을 제작하는데도 영상 생성형 AI는 활용될 수 있다.
5.2. 마케팅 및 광고
영상을 자동으로 생성하는 기술의 발전은 마케팅과 광고 분야에도 영향을 미칠 수 있다. 상품 기획단계 또는 B2B 마케팅에서 활용될 수 있는 상품에 대한 데모 영상을 쉽고 빠르게 제작할 수 있으며 상품의 광고를 위한 소셜미디어 광고 영상, 이메일 마케팅 영상, 브랜드 광고 영상 등 다양한 형태의 광고 영상의 제작도 가능하다. 소비자의 과거 구매내역, 선호도를 바탕으로 제품 추천을 해주는 개인 맞춤형 광고 영상 제작이 시도될 수도 있다.
5.3. 교육
영상 생성형 AI 서비스의 발전은 교육 콘텐츠의 제작에 새로운 기회를 제공할 것으로 예상하는 분석들도 있다(Liu et al., 2024; Intuz, 2024; Acer Corner, 2024). 기존의 교육 자료는 텍스트, 이미지 위주로 제작이 되고 있는데, 영상 생성형 AI의 도입으로 누구나 영상을 쉽게 제작할 수 있게 될 경우 교육 내용을 실감 있는 영상 콘텐츠로 제작할 수 있게 된다. 수학, 과학의 복잡한 개념뿐만 아니라 역사, 사회, 문학의 사건들을 영상으로 제작하여 학생들의 이해를 도울 수 있다. 예컨대, 세포분열 과정을 설명하는 과학교육 영상을 제작하거나 문학 작품의 한 부분(텍스트)을 영상으로 변환하여 학생들을 교육하는 자료로 활용할 수도 있다. 이와 같이 영상 생성형 AI 서비스는 영화·영상 업계뿐만 아니라 영상을 활용할 수 있는 다른 여러 분야에 적용됨으로써 해당 분야에 혁신을 촉매하는 역할을 할 수 있다.
5.4. 게임
현재 Chat GPT와 같은 LLM 기반 생성형 AI뿐만 아니라 이미지 생성형 AI는 게임 업계에 다양한 형태로 활용되고 있다. 게임 개발자 컨퍼런스인 GDC가 개발자 3,000명을 대상으로 실시한 설문조사 결과에 의하면, 개발자 중 49%가 회사 내에서 자신 또는 동료가 생성형 AI를 직무에 활용하고 있다고 응답했다(GDC, 2024). 고도화된 영상 생성형 AI 서비스는 게임에 적용되어 플레이어 동작과 게임 배경을 제작 또는 변화시키는 도구로 활용될 수 있다. 변화하는 기상 조건을 생성하거나, 풍경을 변화시켜 게임의 세계를 보다 창의적이고 다양하게 조성할 수 있다. 현재 이미지 생성형 AI가 NPC7) 제작에 활용되고 있는 것과 같이(파이낸셜뉴스, 2024; BBC, 2024) 영상 생성형 AI도 NPC 제작 또는 게임의 플레이어를 제작하는데 활용될 수 있다. 알고리즘이나 규칙을 사용하여 게임 내의 콘텐츠(레벨, 캐릭터, 물건, 퀘스트 등)를 자동적으로 생성하는 기술을 절차적 콘텐츠 생성(procedural content generation, PCG)이라고 하는데 영상 생성형 AI는 이 분야에 큰 진전을 가져올 수 있을 것으로 예상되고 있다.
- 7) NPC(Non-Player Character) : 게임 안에서 이용자가 직접 조정할 수 없는 캐릭터. 게임 내의 몬스터, 퀘스트를 소개하는 캐릭터 등 그 사례이다.
6. 마치며
전술한 바와 같이 Sora는 아직 기술적으로 극복해야 할 점이 많이 남아 있다. 이미지 생성형 AI 서비스에서도 문제가 됐던 가짜뉴스, 저작권 침해 문제 등에 대한 보완책도 필요할 것으로 보인다. OpenAI는 이용자가 Sora의 프롬프트에 극단적인 폭력(extreme violence), 성적인 콘텐츠(sexual content), 혐오 이미지(hateful imagery), 유명인 유사(celebrity likeness) 콘텐츠, 타인의 IP 요청을 입력할 경우 이를 거부하도록 하고 있다. 그리고 현재 레드 팀을 운영하여 서비스 내의 부정확한 정보(misinformation), 혐오 콘텐츠(hateful content), 편향(bias)을 테스트하고 있다. 그러나 다른 생성형 AI 서비스에서도 문제가 됐던 가짜뉴스, 저작권 침해 문제 등에 대한 이슈는 계속 이어질 것으로 예상된다.
2022년 Chat-GPT가 소개된 이후, LLM 기반 생성형 AI 서비스가 현재 빠른 속도로 발전하고 있는 것과 같이 영상 생성형 AI 서비스도 기술적인 오류와 한계를 해결하며 빠른 속도로 발전할 것으로 보인다. 영상 생성형 AI 기술이 영상미디어 산업뿐만 아니라 각 산업 분야에 가져올 변화를 예측하고 산업적, 제도적 대비책을 고민해야 할 때다.
참고문헌
- 1)파이낸셜뉴스(2024). 생성형AI, 게임 제작 생태계 변화 이끌 것.
- 2)한혜진(2024). 애니메이션 제작을 위한 생성형 AI 기술. 조형미디어학, 27(1), 12-21.
- 3)Acer Corner(2024). Text-to-video AI tools: Comparing Sora and Lumiere.
- 4)Andreessen Horowitz(2024). Why 2023 was AI video’s breakout year, and what to expect in 2024.
- 5)BBC(2024). How the computer games industry is embracing AI.
- 6)EC-PR(2024). Using Midjourney AI Images Commercially – What You Need to Know.
- 7)GDC(2024). 2024 State of the Game Industry.
- 8)Google Research(2024). Introducing Lumiere: A space-time diffusion model for video generation.
- 9)Intuz(2024). OpenAI's Sora: Text-to-video AI model and its potential use cases.
- 10)Liu, Y., Zhang, K., Li, Y., Yan, Z., Gao, C., Chen, R., Yuan, Z., Huang, Y., Sun, H., Gao, J., He, L., & Sun, L.(2024). Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models. ArXiv, abs/2402.17177.
- 11)Los Angeles Times(2024). Washed Out’s new music video was created with AI. Is it a watershed moment for Sora?
- 12)Medium(2024)a. Why Midjourney is so darn good: Confessions from the not-so-secret AI model rating party-goer.
- 13)Medium(2024)b. From text to video: Exploring the capabilities and limitations of OpenAI's Sora.
- 14)New Atlas(2024). Video: Filmmakers test-drive OpenAI’s Sora, inspiring awe – and concern.
- 15)OpenAI(2024). Video generation models as world simulators.
- 16)TechCrunch(2024). Runway’s Gen-2 shows the limitations of today’s text-to-video tech.
- 17)The Washiton Post(2024). The future of AI video is here, super weird flaws and all.
- 18)Variety(2024). Sora AI videos easily confused with real footage in survey test.