
생성형 AI 기술이 등장하고 그동안 다양한 서비스들이 나타났지만 동영상 콘텐츠 제작에 있어서는 그 적용의 한계가 뚜렷했었다. 하지만 지난 2024년 2월에 발표한 OpenAI의 <Sora>는 정식 출시가 아닌 결과물 예시만을 제시했음에도 그 한계가 극복되고 있음을 보여줬다. 기존의 결과물들과 차별화된 높은 품질의 콘텐츠들이 간단한 텍스트 명령만으로 창출되어 업계관계자들은 물론 일반대중들에게까지 특이점이 오고 있음을 느끼게 했기 때문이다. 특이점(singularity)이란 혁신 기술 출현과 같이 어떠한 계기로 인해 환경이 급속히 변함으로써 우리의 생활이 되돌아 갈 수 없을 정도로 변화하는 기점을 뜻한다. 본 글은 동영상 제작에 있어서 특이점을 만들고 있는 <Sora>의 등장이 기존 서비스들과 어떻게 다른지 설명하고, 미디어·콘텐츠 산업에 미칠 영향에 대해 낙관론과 비관론 모두의 관점에서 살펴보고자 한다.
1. 들어가며
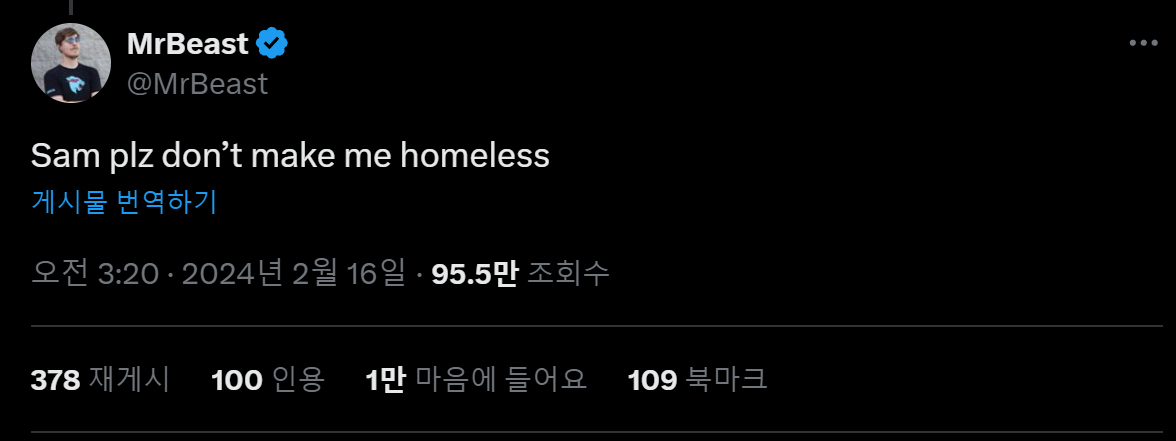
‘특이점(singularity)’이란 혁신 기술 출현과 같이 어떠한 계기로 인해 환경이 급속히 변함으로써 우리의 생활이 되돌아 갈 수 없을 정도로 변화하는 기점을 뜻한다. ChatGPT가 등장하고 생성형 AI가 이러한 기술 특이점이 될 것으로 많은 전문가들은 예측했다. 하지만 이 모델이 세상에 나온 지 불과 1년이 막 지난 시점에 동영상 창작 영역까지 완성도 높게 구현될 것을 예상한 사람은 그렇게 많지 않았을 것이다. 동영상이라는 콘텐츠 자체가 일반적으로 데이터 용량이 클 뿐만 아니라, 보이는 사물마다 모두 다른 움직임을 가지고 있어 각 사물의 각도 마다 다른 물리법칙이 적용되기 때문에 이를 구현해 내는데 시간이 걸릴 것으로 예측됐기 때문이다. 적어도 지난 2024년 2월 OpenAI의 Text-to-Video 서비스인 <Sora>의 예시 콘텐츠들이 공개되기 전까지는 그러한 예측이 맞아보였다. 이전까지 나왔던 동영상 생성형 AI 서비스들의 결과물들은 대부분 짧은 시간의 동영상 콘텐츠를 실험적으로 생성했었다. 그 마저도 이미지들이 연결된 형태의 프레임이 끊기는 형태로 구현됐고, 일부는 물리 법칙이 깨지면서 어색한 움직임과 형태를 그대로 노출했었다. 이러한 상황에서 <Sora>가 구현한 콘텐츠 결과물들을 보게 된 미디어․영상업계 관계자들은 충격이 상당했다. 구현된 동영상 콘텐츠들의 품질이 이전과는 비교할 수 없을 정도로 높아져, 향후 산업 구조 자체를 흔들 정도의 ‘특이점’이 가까이 왔음을 체감했기 때문이다. 대표적으로 전 세계 유튜브 구독자 1위인 유튜버 미스터비스트(Mr.Beast)는 <Sora> 발표 직후 자신의 소셜미디어 X(前트위터)에 “샘(OpenAI CEO), 나를 노숙자로 만들지 마세요”라고 올릴 정도였다.
본 글에서는 특이점을 만들고 있는 <Sora>의 등장이 기존 서비스들과 어떻게 다른지 설명하고, 미디어·콘텐츠 산업에 미칠 영향에 대해 낙관론과 비관론 모두의 관점에서 살펴보고자 한다.
2. 생성형 AI 기반 Text-to-Video 서비스 현황
2-1. OpenAI의 Text-to-Video 서비스 <Sora> 사전 공개
ChatGPT의 개발사인 Open AI는 지난 2024년 2월 15일에 Text-to-Video 서비스인 <Sora>를 사전 공개했다. 이 서비스는 한 줄에서 세줄 정도의 텍스트 명령(프롬프트)을 입력하면 60초가량의 원하는 고품질 동영상 콘텐츠를 출력하는 동영상에 최적화한 생성형 AI 서비스다. 특히, Open AI에서는 서비스 공개와 더불어 ‘Video generation models as world simulators(세상을 시뮬레이션 하는 비디오 생성 모델)’라는 보고서를 발표하며 기술에 대해 구체적으로 설명하기도 했다. 다만, AI 모델이 어떠한 과정을 거쳐 텍스트를 구현하는지에 대한 자세한 내용들은 보고서에 포함되지 않았다.

이 서비스가 제공하는 핵심 기능은 무엇보다도 일관성 있는 고품질 동영상 제공하는 것이다. 이전 서비스들과 차별화되는 특이점은 프롬프트에 대해 공간 모델링을 통해 3D로 생각하고 2D로 시각화하여 피사체를 조각적으로 이해하여 기존 서비스와 차별화된 품질의 콘텐츠 제공하는 것이다. 이를 Open AI는 이를 ‘새로운 시뮬레이션 기능(Emerging simulation capabilities)’이라고 명명했다. 동영상의 사물과 피사체를 퍼즐과 같이 ‘조각’적으로 각각 ‘맥락’에 따라 정리하여 ‘시뮬레이션’한다. 예를 들어, 중력이 다양한 피사체에 미치는 영향 등을 각각 고려하여 결과물을 보여줌으로써 지금까지의 다른 어떤 생성형 AI 서비스보다 훨씬 더 정교하게 결과물의 생생함을 극대화하는 효과를 거두었다. 프롬프트에 중력이 어떻게 작용하는지, 물이 어떻게 튀고, 눈이 어떻게 쌓이는지 설명하지 않아도 맥락적으로 이해하여 텍스트에 따른 가장 적절한 시뮬레이션 결과를 제공한다. 즉, 텍스트 명령만으로 학습한 생성형 AI를 통해 현실처럼 동영상 콘텐츠로 구현해 세상을 시뮬레이팅하는 것이 OpenAI가 강조하고자 하는 <Sora>의 주된 기능이다.

이번 발표는 정식 런칭이 아니라 현재 영상‧디자인 등 관련 분야 전문가에게만 테스트를 진행 중이며, 사전 공개에서는 <Sora>가 생성한 48개의 비디오 콘텐츠 예시를 공유하여 <Sora>가 무엇을 할 수 있는지를 보여주고자 하는 의도였다(The Washington Post, 2024. 2. 22). OpenAI는 공식적으로 서비스를 출시하기 전에 잘못된 정보, 증오, 편견, 성적 내용, 딥페이크 등 사회적 문제를 제기할 수 있는 부분을 사전에 방지하기 위해 전문가를 대상으로 베타 테스트를 진행하고 있다고 밝혔다. 언제 정식 서비스를 제공할지, 어느 정도의 서비스 이용비용을 요구할지, 동영상 콘텐츠에 얼마나 많은 시간과 컴퓨팅이 소비되는지 등에 대한 구체적 정보는 발표하지 않았다.
또한 <Sora>는 텍스트로 동영상을 생성하는 기능뿐 아니라 정적 이미지를 입력하면 그 이미지를 기반으로 동영상 생성하는 애니메이션화, 두 개의 입력 동영상을 자연스럽게 연결하는 비디오 연결, 해상도 조절을 통한 다양한 이미지 생성과 같은 부가적인 기능 역시 제공한다고 발표했다.
2-2. 기존 유사(Text-to-Video) 서비스 현황
사실, AI 기술을 통해 동영상 콘텐츠를 생성하는 서비스는 일찍부터 상용화를 시도하고 있었으며, 이미 ChatGPT 등장 이전부터 다양한 서비스가 개발되기도 했다. 미국의 스타트업 런웨이(Runway)는 2018년에 온라인 영상 편집 및 제작 서비스로 시작하여, 생성형 AI 기술의 접목도 가장 빠르게 진행했다. 텍스트, 이미지 또는 영상 등 다양한 유형의 데이터(모달리티)를 입력하면 그에 맞게 동영상을 생성하는 동영상 생성 멀티모달 인공지능인 <Gen-2> 모델을 활용하여 Text-to-Video 서비스를 선도적으로 제공했다. 지속적으로 기능의 업데이트를 진행한 런웨이는 현재 홈페이지를 통해 텍스트를 동영상으로 만드는 기능, 이미지를 동영상으로 만드는 기능, 이미지와 텍스트를 동영상으로 만드는 기능 등을 제공하고 있다. 여기에 더해, 모션 브러쉬를 활용하여 브러쉬로 지정된 피사체를 마음대로 움직일 수 있는 모션 브러쉬 기능을 탑재하면서 서비스의 활용성을 높이기도 했다. 한편, 2023년 12월에는 대표적인 이미지 데이터베이스 회사인 게티 이미지(Getty Images)와 제휴하는 등 다양한 이미지 데이터를 확보하여 결과물에 대한 품질 개선 노력을 진행하고 있다.
피카랩스(Pika Labs)도 2023년 11월 28일에 Text-to-Video 서비스인 <Pika>를 런칭하면 이 분야의 초기 사업자로 자리했다. 베타버전으로 무료 출시하면서 최초 텍스트 명령어로 3초 분량의 영상을 생성하고, 이후 직전 영상과 연결되는 4초 분량의 영상을 추가로 생성하면서 최대 15초의 영상 콘텐츠를 제작하는 방식을 취했다. 최근에는 유료가입자를 대상으로 다양한 고급 기능을 제공하면서 비즈니스 모델을 다각화하고 있다. 특히 <Sora> 등 다른 Text-to-Video 서비스들은 음성을 제공하지 못하고 있다는 점을 착안하여 2024년 3월부터 음향효과 기능을 추가하여 AI로 비디오와 음성, 음향 등 모든 작업을 수행할 수 있는 최초의 ‘올인원’ AI 비디오 제작 플랫폼을 구축했다. 음향 효과까지 포함되어 더 긴 고품질 동영상 콘텐츠를 생성할 수 있는 프로 구독자의 유료 구독비는 월 58달러로 책정하여 서비스를 제공하고 있다.
한편, '스태이블 디퓨전'이라는 생성형 AI 기반 Text-to-image 서비스로 유명세를 탄 스태빌리티 AI(Stability AI)도 Text-to-video 서비스인 <Stable Video Diffusion>을 2023년 11월에 출시했다. 이 서비스는 텍스트 프롬프트 명령에 따라 초당 24프레임의 영상 콘텐츠를 제공하며, 25개의 생성 프레임과 24개의 FILM 보간 프레임으로 구성된 2초 분량의 동영상 콘텐츠를 평균 41초 내의 분량으로 제공한다. 텍스트 기반 프롬프트 외에도 여러 개의 비디오 클립을 연결, 긴 동영상을 만들 수도 있다.

Stable Video Diffusion
Stability AI’s First Open Video Model.
Stable Video Diffusion is designed to serve a wide range of video applications in fields such as media, entertainment, education, marketing. It empowers individuals to transform text and image inputs into vivid scenes and elevates concepts into live action, cinematic creations.
2-3. 빅테크 기업의 Text-to-Video 서비스 시도
생성형 AI 시장의 주도권을 두고 치열한 경쟁을 시도 중인 글로벌 빅테크 기업에서도 Text-to-video 서비스 모델을 개발하고 출시를 본격적으로 준비하고 있다. 먼저, 구글(Google)은 비디오 생성용 시공간 확산 모델(Space-Time Diffusion Model for Video Generation)을 적용한 동영상 생성 모델 <Lumiere>를 지난 2024년 1월에 발표했다. 모델 발표에서는 텍스트나 이미지 입력으로부터 생성되는 동영상 콘텐츠의 공간적 사실성과 시간적 일관성 개선을 시도한 것이 눈에 띄었다. 이를 위해 비디오 속 사물이 있는 위치에 대한 공간적 측면과 동영상 전체에서 사물이 어떻게 움직이고 변화하는지에 대한 시간적 측면을 동시에 처리하도록 설계했다. 생성한 동영상 콘텐츠의 품질을 높이기 위해 이 모델은 캡션이 달린 3,000만개의 비디오 데이터 셋(data set)으로 학습했으며, 1024×1024픽셀의 초당 16~80프레임으로 최대 5초 길이의 동영상 콘텐츠를 생성하는 것으로 발표했다. 특히, 동영상 콘텐츠의 일부가 손실되어 일부분이 잘 나오지 않는 것도 특정 개체를 삽입하는 인페인팅 기능을 통해 주위 화면을 인식해 완벽히 복원하는 것을 제시하면서, 얼마나 모델이 동영상 맥락을 잘 이해하고 일관성을 유지하는 지 보여줬다.
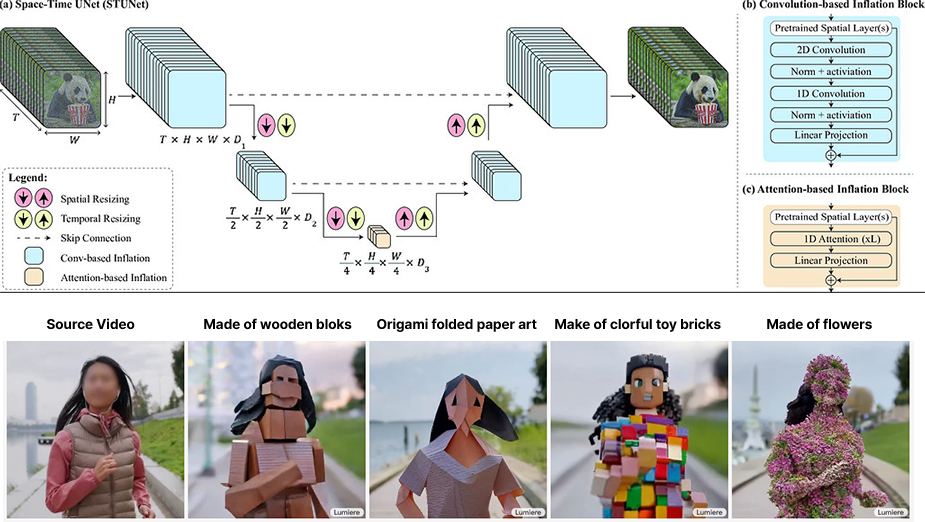
Google의 <Lumiere> 모델
(a) Space-Time UNet(STUNet)
- T, W, H
-
Convolution-based Inflation
- Skip Connection
- Spatial Resizing down, Temporal Resizing down
-
Convolution-based Inflation
- Skip Connection
- Spatial Resizing down, Temporal Resizing down
-
Attention-based Inflation
- Spatial Resizing up, Temporal Resizing up
- Convolution-based Inflation
- Spatial Resizing up, Temporal Resizing up
- Convolution-based Inflation
- text-to-video generation results
(b) Convolution-based Inflation Block
- Pretrained Spatial Layers(s)
- 2D Convolution
- Norm + activiation
- 1D Convolution
- Norm + activiation
- Linear Projection
- + 반복
(c) Attention-based Inflation Block
- Pretrained Spatial Layers(s)
- 1D Attention
- Linear Projection
- + 반복
비디오 스타일화 예시
Source Video, Made of wooden blocks(Lumiere), Origami folded paper art(Lumiere), Make of clorful toy bricks(Lumiere), Made of flowers(Lumiere)
한편 메타(Meta) 역시, 2023년 11월에 Text-to-video 서비스 모델인 <Emu Video>를 논문 발표와 함께 공개한 바 있다. 이 서비스 모델은 텍스트 입력이나 참조 이미지를 입력하여 동영상 콘텐츠를 생성하거나 두 개의 동영상을 합치는 기능이 가능하며, 이를 통해 4초 길이의 동영상 클립 콘텐츠를 생성할 수 있다.

Meta의 <Emu Video> 모델
Factorized text-to-video generation involves first generating an image I conditioned on the text p, and then using stronger conditioning–the generated image and text–to generate a video V. To condition our model F on the image, we zero-pad the image temporally and concatenate it with a binary mask indicating which frames are zero-padded, and the noised input.
동영상 예시
프롬프트 : A fox dressed in a suit dancing in a park.
다만, 구글의 <Lumiere>, 메타의 <Emu Video>, 이 두 서비스는 논문과 모델 발표는 진행했지만, 아직 정식 런칭은 이루어지지 않았다.
2-4. <Sora>가 가지고 온 특이점
기존의 Text-to-Video 서비스들도 텍스트 입력만으로도 동영상 콘텐츠를 자동으로 만든다는 점에서 창작자들과 일반 대중들에게 높은 화제성을 이끌고, 많은 기대를 가지게 했었다. 그럼에도 불구하고 기존 서비스의 결과물들은 화질이나 디테일 무너지는 건 당연하고 프레임이 충분하지 않아 뚝뚝 끊기는 현상이 보인다는 한계성이 분명했었다. 마치 여러 이미지를 붙인 것 같이 구현되어 결과물 화면이 튀거나 일렁이는 현상이 발생하곤 했었다. 그래서 광고나 영화, 드라마, 뮤직비디오와 같은 동영상 콘텐츠 실무에는 적용하기 어렵다고 전문가들은 평가했었다.
하지만, <Sora>의 경우 프레임이 굉장히 자연스럽고 맥락에 맞는 일관성이 60초라는 상대적으로 긴 시간동안 지켜져 이전과 비교해서 엄청난 품질의 향상을 느끼게 만들었다. 물론 예시로 제안된 결과물들이었지만 이들 결과물들은 편집과 컷이 세련되게 자동으로 이루어지고, 빛에 대한 이해와 안경이나 선글라스와 같은 소품으로 굴절되는 현상은 물론, 슬로우 모션이나 구도, 앵글과 같은 연출이 매우 자연스러웠다. 놀랍도록 일관성 있고 실제와 같은 공간과 피사체 표현이 가능하기 때문에 고정된 사진을 붙이는 방식이라기보다는 게임엔진을 학습하여 3D 모델링을 구현하는 것으로 전문가들은 추측하기도 했다(Gizmodo, 2024. 2).
정식 런칭이 아니라 <Sora>가 생성한 48개의 동영상 결과물 예시를 보여주는 사전공개 발표였음에도 불구하고 영상업계에서의 충격은 상당했다. 기존에도 생성형 AI 동영상 제작 서비스들이 있었지만 결과물의 품질이 이전과 비교할 수 없을 정도로 향상되어, 이 서비스가 산업구조 전체를 변화시킬 수 있겠다는 ‘특이점’ 가능성을 업계가 체감했기 때문이다. 그렇다면 실제로 생성형 AI를 통한 동영상 콘텐츠 제작은 미디어‧콘텐츠산업에 어떠한 영향을 미치게 될까? 그리고 이러한 급격한 변화는 향후 업계에 위기로 작용하게 될까 혹은 기회로 작용하게 될까?

주프롬프트를 “Beautiful, snowy Tokyo city is bustling. The camera moves through the bustling city street, following several people enjoying the beautiful snowy weather and shopping at nearby stalls. Gorgeous sakura petals are flying through the wind along with snowflakes.”로 공통적으로 입력
3. 미디어·콘텐츠 산업에 미칠 영향: 위기인가 기회인가?
3-1. 비관론
생성형 AI가 출현한 시기부터 지속적으로 우려가 되고 있는 부분은 일자리 이슈이다. 미국 기업 3곳 중 1곳은 생성 AI로 직원을 대체하고 있다는 조사 결과도 있으며(Resume Builder, 2023) 골드만삭스는 AI 도입의 생산성 향상 효과가 신흥국보다 선진국에서 클 것이며 미국 등 선진국 업무의 25%, 신흥국 업무의 20%를 자동화 할 것으로 예측하기도 했다(Goldman Sachs, 2023).
특히 인간의 영역이라고만 생각했던 창작의 영역까지 다량의 창작물 데이터의 학습을 통해 생성형 AI가 결과물을 내기 시작하자 미디어‧콘텐츠 업계는 물론 일반 대중들까지 우려의 목소리가 커졌다. 이러한 관점의 연장선상에서 <Sora>와 같은 Text-to-Video 서비스는 촬영 없이 특수한 상황까지 AI를 통해 동영상 제작이 가능해지기 때문에 직접 촬영 시 발생하는 인력의 감축을 예상할 수 있게 한다. <Sora>의 예시 동영상들의 장면을 예로 들자면, 공중에서 보이는 장면을 촬영하기 위해 하늘에서 촬영하는 드론 기사가 필요 없어지며, 안정되고 개성 있는 카메라 앵글을 촬영하기 위해 카메라 촬영에 필요한 레일이나 그립 팀이 굳이 요구되어지지 않는다. 또한, 군중처리를 위한 CG처리, 엑스트라 인원, 로케이션 매니저 등의 역할과 효용성이 급격히 떨어지게 된다. 게다가 단발성 광고나 뮤직비디오, 독립영화 등 상대적으로 배우의 브랜드가 크게 필요 없는 영상콘텐츠의 경우 주연, 조연, 기타 연기 부분의 출연료 비용도 없앨 수 있게 된다. 이러한 우려로 인해, 실제로 2023년 할리우드의 작가조합과 메이저 스튜디오들은 주요 쟁점이었던 인공지능(AI) 대본 활용 이슈로 148일간 파업을 진행하기도 했다.

미국 작가조합 AI 관련 넷플릭스 앞 시위<좌>
AI를 통해 대체 및 위기 직종 예시<우>
| 역할 | AI 대체 위기 직종 |
|---|---|
| 촬영 | 촬영 감독, 촬영팀 |
| 배경/세트 디자인 | 미술 감독, 미술팀, 그래픽디자이너 |
| 군중 처리 | 엑스트라, 그래픽 디자이너 |
| 후가공 | 그래픽 디자이너, 편집자 |
| 조명 | 조명 감독/조명팀 |
| 드론 촬영 | 드론 기사 |
| 주연/조연/기타 연기 | 배우 |
다음으로 가짜뉴스(Fake News), 딥페이크(Deep Fake) 이슈 역시 미디어·콘텐츠 산업에 악영향을 미치는 요인으로 지적되고 있다. 잘못된 정보를 유포하거나 허위 콘텐츠를 조작하는 데 잠재적으로 오용될 수 있다는 우려로, 생성된 동영상은 부정확한 정보를 제공하거나 시청자를 속이기 위해 쉽게 조작할 수 있기 때문이다. 국제전기전자학회 표준협회(IEEE)는 잘못된 정보 유포, 공격적이거나 유해한 콘텐츠 생성, 조작이나 협박을 위한 딥페이크 콘텐츠 생성 등 악의적인 목적으로 AI 콘텐츠 생성 서비스를 오용할 가능성이 있음을 강조(Institute of Electrical and Electronics Engineers, 2023)한 바 있다. AI 개발자 Havemeyer도 워싱턴포스트지와의 인터뷰에서 2024년 대선을 앞둔 상황에서 AI를 통한 Fake 뉴스는 더욱 주의해할 것으로 지적(Washington Post, 2024)하기도 했다. 게다가 딥페이크 기술은 단순 개인의 인권침해를 넘어 국가와 사회적 혼란까지도 초래할 수 있다. 유명인이나 지인의 초상권을 성적인 용도로 딥페이크 작업을 하여 인권 침해를 일으키는 문제도 발전 초기인 현재에도 심각하게 나타나고 있기 때문이다.
한편, 데이터 오염과 할루시네이션(환각현상)이 초래할 사회적 혼란도 예상해 볼 수 있는 악영향 시나리오 중 하나이다. 현재까지 가장 완성된 형태로 예측되는 <Sora>의 예시 영상에서도 잘못된 오류가 많이 발견되고 있다. 체스의 왕이 3개 존재하고 체스 판이 8X8이 아니라 7X7이거나, 촛불을 불었지만 촛불이 그대로 있기도 하고, 의자를 옮기는 중에 모래가 겹치는 등 오류들이 다수의 콘텐츠들에서 발견됐다. 문제는 AI는 시중의 데이터를 가지고 강화학습을 통해 새로운 동영상 결과물을 산출한다는 데 있다. 잘못된 정보가 반복되면 잘못된 정보가 사실처럼 받아들이는 경우가 생길 수 있기 때문이다. 특히, 최근 들어 숏츠 동영상을 Text-to-Video 서비스를 활용하여 제작하고 있는 콘텐츠가 넘쳐나고 있는데, 이러한 콘텐츠들이 반복적으로 누적되면 이들이 학습되는 원천 데이터의 주(主)가 될 수 있다. 즉 AI가 생산한 데이터가 다수를 차지하게 되면 결국 오염된 정보를 지속적으로 강화학습하게 되어 개선의 여지가 사라지게 될 수 있다. 이로 인해 모든 미디어 환경이 오염된 데이터와 콘텐츠로 가득한 사회가 올 수 있다.
3-2. 낙관론
앞서 설명한 생성형 AI를 통해 미디어․콘텐츠 산업 관련 일자리가 사라질 것이라는 의견에 대해 반대 의견을 제시한 전문가들도 많다. 즉, 지금까지 새로운 기술이 등장하거나 혁명이 발생할 때마다 다수의 일자리들이 사라지기도 했지만, 오히려 더 많은 일자리들이 발생했다는 것이다. 실제로 미국의 직업군별 고용 분포를 연구한 한 보고서에서는 지난 80년 동안 미국 뉴욕시 고용의 85%가 1940년 전에 없었던, 새로운 직종이라는 분석을 토대로 혁신기술이 새로운 직종을 창출할 것으로 주장(NATIONAL BUREAU OF ECONOMIC RESEARCH)했다. 생성형 AI로 제작을 하더라도 결국 어떤 동영상 콘텐츠가 품질이 높고, 어떠한 구성에서 어떠한 각도가 좋은 결과물인지, 완성품을 선택하고 수정하는 것은 전문가 영역에서 할 수 있는 부분이다. 따라서 노동력이 많이 드는 단순 업무는 줄어드는 반면, 전문성을 요구하는 아이디어나 창작력이 많이 요구되는 다양한 직업군이 발생할 수 있다는 의견이다.
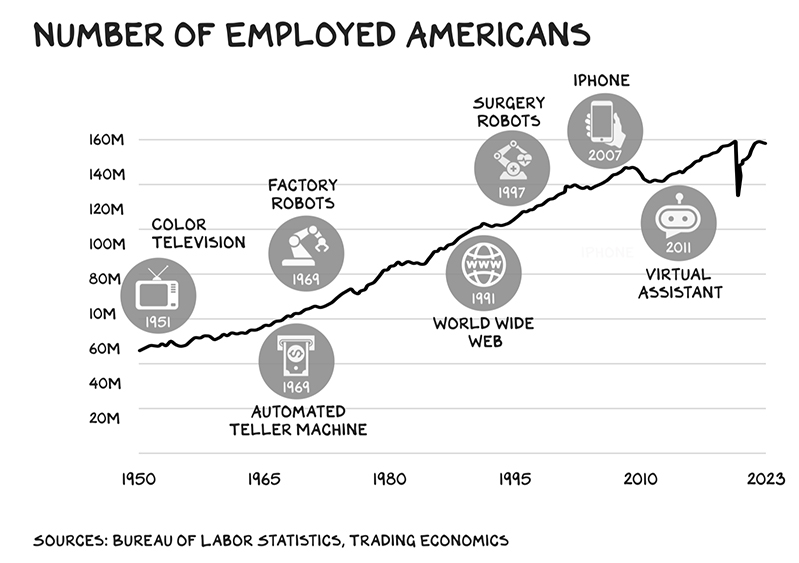
NUMBER OF EMPLOYED AMERICANS
- 1951 COLOR TELEVISION
- 1969 AUTOMATED TELLER MACHINE
- 1969 FACTORY ROBOTS
- 1991 WORLD WIDE WEB
- 1997 SURGERY ROBOTS
- 2007 IPHONE
- 2011 VIRTUAL ASSISTANT
SOURCES : BUREAU OF LABOR STATISTICS, TRADING ECONOMICS
한편, 생성형 AI를 통한 콘텐츠 제작에 있어서 낙관론을 주장하는 전문가들의 핵심 의견 중 하나는 제작비용 감소와 제작 진입장벽 감소로 인해 창의력 있는 창작자의 콘텐츠 제작기회가 늘어날 것이라는 것이다. 일예로, 스마트폰으로 인해 카메라 성능이 발달되고 온라인 네트워크 활성화로 누구나 쉽게 유튜브와 같은 플랫폼을 통해 방송 콘텐츠 제작이 가능하게 되자 대중 창작자의 수가 기하급수적으로 늘어난 바 있다. 여기에 더 나아가 생성형 AI로 인해 영상콘텐츠의 제작비가 감소하고 제작 방식이 쉬워짐에 따라 그동안 진입장벽이 높았던 영화 콘텐츠나 방송 콘텐츠의 제작까지 개인 수준에서도 가능해지는 시대가 열릴 수도 있다. 1인 독립영화로 시작해서 AI를 통해 블록버스터 콘텐츠까지 제작이 가능해지면 장편영화까지 소수나 개인이 콘텐츠를 제작할 수 있는 여건이 열릴 것으로 기대할 수 있다. 게다가 촬영만으로는 구현할 수 없는 상황까지 상상력을 영상으로 표현할 수 있는 요건이 마련되기 때문에 창작 표현의 한계가 무한하게 확장될 수 있다.
여기에 더해, 다양한 콘텐츠가 생산되는 것은 자연스럽게 다양한 콘텐츠를 향유할 수 있는 소비 환경을 열 수 있다. 이전에 TV전파를 통한 지상파 방송 시청과 같이 한정된 유통 환경에서만 콘텐츠를 시청할 수 있을 때는 전 국민의 대다수가 시청하는 드라마나 방송 프로그램이 많았었다. 하지만 현재 케이블TV에서부터 OTT 등 다양한 채널을 통해 콘텐츠를 접하게 되자 다양한 콘텐츠들이 각자의 주제를 자신들만의 방식으로 표현하게 됐고 소비자 취향의 파편화가 이루어져, 초개인화를 촉진했다. 이러한 흐름의 연장선상으로 생성형 AI를 통해 더욱 다양한 콘텐츠를 소수나 개인이 만들 수 있게 될 경우 소비자의 콘텐츠 향유 다양성 역시 증진될 수 있다.
마지막으로 국내의 콘텐츠 IP 경쟁력이 더 제고되어 글로벌 수출이 더 활성화될 수 있는 환경이 열릴 수도 있다. 먼저, 실시간 번역과 통역이 AI를 통해 자유롭게 이루어지며 전 세계 콘텐츠 소비자들이 한 곳에 모이는 글로벌 원마켓(One-Market)이 더욱 강화 될 것으로 예상된다. 넷플릭스, 유튜브 등 전 세계인이 동시에 시청하는 글로벌 플랫폼 등장으로 인해 글로벌 소비자들이 하나의 플랫폼에 집중되는 현상이 발생되어 콘텐츠 경쟁력은 있었으나 노출 기회가 없었던 K-콘텐츠가 기회를 얻는 수혜를 받았었다. AI 통번역이 더 고도화되고 입술과 표정의 AI 편집이 쉽게 가능해지면 전 세계 콘텐츠가 모두 모국어로 들리는 환경이 열리게 되고, 콘텐츠의 기획과 제작에 있어서 전 세계의 소비자의 보편성과 문화적 코드를 고려한 전략이 요구되어질 것이다.
또한 경쟁력 있는 IP의 확장이 폭발적으로 이루어져 그 영향력이 증대될 것 역시 기대된다. 잘 개발된 캐릭터와 이미지 한 장이 쉽게 웹툰과 애니메이션 콘텐츠가 될 수 있을 뿐 아니라 영화/방송 콘텐츠로까지 자유롭게 확장이 가능할 수 있다. 즉 생성형 AI를 통해 웹툰과 웹소설 콘텐츠가 애니메이션이나 영화/방송 콘텐츠로 제작되는 OSMU가 더욱 활성화되어 IP 비즈니스는 더 고도화 될 것으로 예상된다. 배우나 아이돌 IP의 활용도도 높아져 이들이 직접 촬영장에서 제작에 참여하지 않고 초상권을 제공하기만 해도 콘텐츠를 만들 수 있는 환경이 열릴 수도 있다. 이는 팬덤 비즈니스가 발전된 K-콘텐츠에게 있어 새로운 기회와 비즈니스 확대를 제공할 수 있다.
4. 나가며
지금까지 생성형 AI 기반 동영상 제작 서비스인 <Sora>에 대해 살펴보면서 이 모델이 미디어․콘텐츠산업에 어떠한 영향을 미칠 지에 대해 살펴보았다. 유감스럽게도 미래를 다녀오지 않는 한, 우리는 그 영향력이 미디어․영상 업계에 위기를 초래할 것인지 또는 기회를 만들어 낼 것인지 정확하게 예측하기는 어렵다. 다만, 과거의 사례를 비추어 새로운 기술 혁신이 미디어․콘텐츠산업에 어떻게 영향을 미쳤는지 살펴볼 필요는 있다. 역사적으로 살펴볼 때, 미디어․영상 산업만큼이나 기술의 영향력을 크게 받은 산업은 찾아보기 힘들다. 초상화 등 그림을 그리던 것에서 사진 기술이 개발되면서 다양한 이미지 콘텐츠 산업이 발생했다. 또, 연극과 같이 현장에서 퍼포먼스를 하던 것을 카메라 기술을 통해 필름에 담아 스크린에 구현하면서 영화 산업이 발생했다. 이후 전파기술과 TV 기술이 발전하여 집에서도 영상을 볼 수 있게 되면서 드라마, 예능, 뉴스, 스포츠와 같은 방송 콘텐츠가 발생했다. 스마트폰이 개발되어 대중화된 이후 인터넷/모바일 네트워크와 글로벌 플랫폼을 통해 개인이 방송을 하고, 개인이 비즈니스 모델을 창출하는 시대가 열렸다. 그리고 이번엔 생성형 AI 기술이 다음의 변화를 기다리고 있다. 새로운 기술은 초상화를 그리는 화가, 동네에서 공연하는 공연자, 심지어는 레거시 방송 산업 종사자 등 기존 산업의 일자리와 산업 파이의 크기를 줄이기도 했다. 하지만 이러한 패러다임 변화를 미리 파악하고 빠르게 미디어 산업에 접목한 사업자들은 새로운 시장 변화의 선도자가 됐다. 가깝게는 넷플릭스가 그랬고, 유튜브와 같은 뉴미디어에서 활약하고 있는 크리에이터들이 그랬다. 따라서 이러한 변화를 목도하고 있는 실무자들은 생성형 AI가 일으키고 있는 변화들을 추적하며 다양한 서비스를 직접 활용해보고, 미디어 콘텐츠 산업에 어떠한 기회가 찾아올지 살펴보는 노력이 지속적으로 필요하다. 또한 정부 차원에서도 한국 콘텐츠의 글로벌 위상을 보장하기 위해서, 생성형 AI 서비스 활용 확대로 나타날 수 있는 미디어․콘텐츠산업계 변화와 국제사회 이슈에 대한 적극적이고 선제적인 정책 대응이 필요한 시점이다.
참고문헌
- 2) AI 타임스(2024. 3. 12). 피카, 동영상 생성 AI에 음성 이어 사운드 효과 추가.
- 8) AI 타임즈(2024. 7. 14). 할리우드, 생성 AI '디지털 복제 배우' 쟁점 부각.
- 12) DBR(2024. 4). 동영상 생성 AI 'Sora'가 던진 숙제.
- 추가 Emu Video Paper.
- 5) Gizmodo(2024. 2. 15). OpenAI’s Video Generator Sora Is Breathtaking, Yet Terrifying.
- 7) Goldman Sachs(2023. 11. 7). AI may start to boost US GDP in 2027.
- 9) Institute of Electrical and Electronics Engineers(2023. 1. 18). IEEE Introduces New Program for Free Access to AI Ethics and Governance Standards.
- 추가 Lumiere 홈페이지.(https://lumiere-video.github.io/)
- 3) Marketing-interactive(2024. 2. 19). Sora for dummies: 101 on OpenAI's new text to video AI model.
- 추가 MrBeast X페이지.
- 추가 Open AI 홈페이지.(https://openai.com/sora/)
- 추가 Pika 홈페이지.(https://pika.art/about)
- 11) Profgalloway(2023. 2. 3). Number of employed Americans.
- 6) Resume Builder(2023. 11. 8). 1 in 3 Companies Will Replace Employees With AI in 2024.
- 추가 runway 홈페이지.(https://runwayml.com/)
- 추가 Stability Ai 홈페이지.(https://stability.ai/stable-video)
- 1) The core(2024. 2. 18). OpenAI 소라(Sora), 숨겨진 혁명 이야기.
- 4) Washington Post(2024. 2. 16). OpenAI shows off lifelike videos generated by Sora, its new AI tool.
- 10) Washington Post(2024. 4. 23). AI deepfakes threaten to upend global elections. No one can stop them.
- 추가 YouTube. AI Community 채널. 최신 기술 AI SORA와 플랫폼별 비교 영상.